How to Structure Content That AI Systems Actually Cite
You can have the best research, the strongest data, and the most authoritative domain - and still get zero AI citations. The problem usually isn't what you wrote. It's how you structured it.
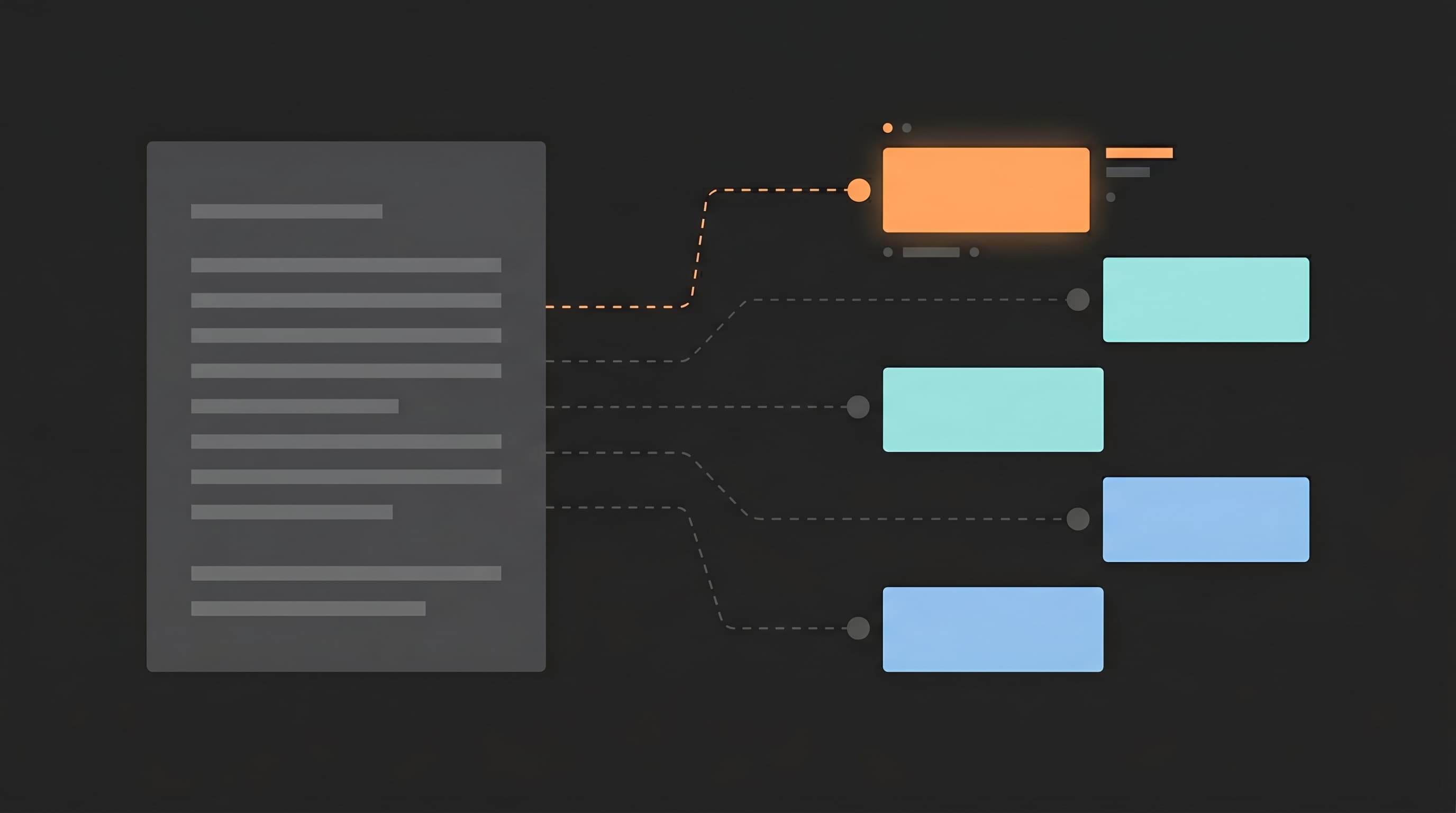
AI systems don't read articles top to bottom. They chunk pages by headings, convert each chunk to a vector embedding, and retrieve the chunks most semantically similar to the user's query. If your structure doesn't match how they extract, your content is invisible to them. This guide covers what the research says about body content architecture - paragraph length, heading format, answer placement - and what restructuring actually produces.
Key Takeaways
- 55% of AI Overview citations come from the first 30% of page content; 44% of ChatGPT citations follow the same pattern - front-load your answers (CXL, ALM Corp)
- RAG systems treat H2/H3 headings as chunk boundaries - each section is retrieved and ranked independently, not as part of the full article (Weaviate, Nvidia)
- Question-format H2 headings that match query wording get cited 3.1x more than generic headings in AI Overviews (Searchforged)
- Answer-first sections (direct answer in first 40-60 words) triple featured snippet capture and increase ChatGPT citations by 140% (TurboAudit)
- Optimal extractable passage: 100-300 words per section with a 40-80 word answer lead, matching the 134-167 word units AI Overviews typically extract
- Rewrite your top 10 pages so every H2 opens with a direct answer that works if quoted alone
How Do AI Systems Extract Content From Your Page?
AI search products don't retrieve whole articles. They break your page into chunks, convert each chunk to a vector embedding, and retrieve the chunks most semantically similar to the user's query. Your article as a whole doesn't matter for retrieval. Individual sections do.
The chunking process follows a consistent pattern across RAG systems. Documentation from Weaviate, Nvidia, Pinecone, and Zilliz all confirm that HTML heading tags (H2, H3) function as primary chunk boundaries. The text between one H2 and the next becomes a single retrievable unit. Each unit gets its own embedding and competes independently against every other chunk on the internet for the same query.
This has practical consequences. A long, unbroken paragraph exceeding the chunk size budget gets split by sentence - you lose control over what the AI treats as a coherent unit. Several short paragraphs under the same heading get merged into one chunk. The system is trying to create semantically complete "answer units," and your heading structure determines where those boundaries fall.
Two pages with identical information can have completely different citation rates because of this. A page structured as a wall of text with vague subheadings gets chunked into fragments that mix multiple ideas. Each fragment's embedding captures a blurred average of those ideas, reducing cosine similarity to any specific query. A page structured with focused H2 sections - each covering one question - produces chunks with tight embeddings that match specific queries cleanly.
How closely your chunk matches the query matters enormously. An Aimodeboost study of 15,847 AI Overview results found that content with cosine similarity scores above 0.88 to the query shows 7.3x higher selection rates than content below 0.75. The tighter your section's focus matches a likely query, the higher the embedding similarity, and the more likely it gets retrieved.
For a deeper look at how AI engines decide which sources to include, see How AI Answer Engines Actually Select Content.
Why Does the First Third of Your Content Get Most Citations?
More than half of AI citations come from the top of the page. A CXL study of 100 AI Overview pages found that 55% of citations come from the first 30% of content, while only 21% originate from the bottom 40%. An ALM Corp analysis of 1.2 million ChatGPT responses confirmed the same pattern: 44.2% of citations from the first third.

This isn't arbitrary. It reflects a documented phenomenon in how language models process context.
The "Lost in the Middle" study (published in Transactions of the ACL, 2024) tested multiple models on multi-document QA tasks and found a U-shaped accuracy curve. Models attend most strongly to information at the beginning and end of the context window. Information in the middle degrades performance substantially - sometimes below a closed-book baseline. LangChain has already added a LongContextReorder strategy specifically to counteract this effect by placing the most relevant documents at the start and end. Position bias is one stage in a multi-step retrieval pipeline — the position-bias and rerank mechanics that make first-third placement load-bearing across AI engines covers the upstream stages this bias sits inside.
The implication is structural, not just positional. Your best answer needs to be near the top of the page AND near the top of each section. Every H2 section that buries the answer under two paragraphs of context is fighting the primacy bias built into the models reading it.
This means the common blog pattern of "intro paragraph, then context, then finally the answer" is exactly backwards for AI citation. The answer should be the opening sentence. Context and evidence should follow. If an AI system retrieves your section and the first 60 words are background information, it will often skip to a competitor whose section opens with a direct answer. Erlin's Perplexity SEO guide cites a Princeton/Onely study showing that domains structuring content with the direct answer in the first 40-60 words of each section are cited 65% more frequently than those with unstructured text.
Which Heading Formats Get Cited Most?
Question-format headings outperform statement headings by a wide margin across every platform with available data.
A Searchforged analysis of AI Overview citations found that pages with H2 headings closely matching the query wording are cited at 3.1x the rate of pages with generic headings for the same topic. 61% of AI Overviews pull text from a specific subsection rather than the introduction - the H2 heading determines which section gets selected.
The ALM Corp ChatGPT study (1.2M responses, 18,012 verified citations) found that cited content was twice as likely to include question marks, and 78.4% of citations containing questions came from headings. Question-style H2 tags are treated as prompts whose following paragraphs act as answer spans.
On Perplexity, the effect is equally clear. TryAnalyze's study of 65,000 citations found that Q&A or direct-answer layouts achieve a 55% Top-3 source rate versus a 31% average - roughly 1.8x relative advantage. Perplexity's parser uses H2 and H3 headings as section identifiers, scanning them for matches to the sub-queries it generates from the user's question.
Heading hierarchy matters independently of format. An AirOps study of 12,000+ URLs concluded that well-structured H1-H2-H3 hierarchies nearly triple citation rates relative to content with poor or inconsistent heading structure. Skipping levels (H2 to H4, for example) degrades retrieval accuracy by 30-40%.
The conversion is straightforward:
| Generic Heading | Question-Format Heading | Why It Works |
|---|---|---|
| "Content Structure" | "How Should I Structure Content for AI?" | Mirrors query phrasing |
| "Benefits of Schema" | "Why Does Schema Markup Improve Citations?" | Matches question intent |
| "Best Practices" | "What Are the Most Effective Content Formats?" | Aligns with how users ask |
| "Pricing Overview" | "How Much Does Content Optimization Cost?" | Natural language match |
The test: would a real person type this heading into ChatGPT? If not, rewrite it.
What Is the Right Section Length for AI Extraction?
AI systems extract passages, not articles. The passages they select cluster around a specific size range.
A Wellows and Ziptie analysis of AI Overview extractable units found they cluster around 134-167 words, with 62% of featured passages between 100 and 300 words. These are long enough to be self-contained but short enough for efficient passage-level ranking.
The practical structure is an "answer module": a 40-80 word direct answer lead followed by 60-220 words of supporting evidence. ICODA's 2026 optimization guide recommends placing the clearest answer within the first 50-70 words of each section. Agenxus' Perplexity playbook specifies "concise, self-contained passages of 100-300 words" as the target for extraction efficiency.
Agenxus breaks this down into an Answer-Evidence-Depth pattern: roughly 50 words of direct answer, 100-150 words of supporting evidence (data, sources, examples), and optional additional depth. This matches how AI systems extract - they grab the answer lead for the synthesized response and use the supporting evidence for attribution confidence.

The key principle is section independence. Apply a "snippet test": if someone saw only this section with no surrounding context, would it answer a specific question clearly? If it requires the previous section to make sense, it's not self-contained enough for AI extraction.
This is where most content fails. Traditional writing builds arguments progressively - context first, then evidence, then conclusion. AI extraction inverts this. The conclusion (the answer) needs to come first, because that's what the retrieval system matches against the query. The context and evidence support the answer but don't replace it.
Structure articles as a cluster of independent answer modules connected by headings, not as a single linear narrative. Each section should function as a standalone answer that happens to live inside a larger article.
For content formatting patterns that complement this approach, see Add a TL;DR Block. Get More AI Citations. For the metadata layer that works alongside body structure, see Schema Markup for AI Citations.
What Does Restructuring Actually Produce?
The data from companies that have restructured body content (not just added schema or metadata) shows consistent gains.
A 2026 case study of a telehealth platform that reworked its top 50 informational pages - converting subheadings to question-led H2s, adding 50-70 word answer paragraphs under each heading, tightening paragraphs to one idea each - saw AI Overview citation frequency increase roughly 3x within 60 days. Branded search volume grew 22% over the same period.
A service business case study documented a move from zero AI Overview keywords to 90+ in four months, with 2,300% increase in AI-driven traffic. The documented changes: logical H2/H3 hierarchies, standalone paragraphs, and key insights moved to the top of articles.
At the controlled-experiment level, TurboAudit's answer-first tests found that placing a direct answer in the first 40 words of each section tripled featured snippet capture (8% to 24%) and increased ChatGPT citation rates by 140%.
The Princeton GEO experiments (KDD 2024, 10,000 queries) showed that structural changes alone - adding citations, statistics, and clearer formatting - produced 30-40% visibility improvements across generative engines. No link building. No domain authority changes. Just structure.
These results are additive with metadata optimizations like schema markup. Structure makes your content extractable. Schema makes it identifiable. Both increase citation probability, but structure is where most content fails first.
Where to start: Pick your 10 highest-traffic pages. For each one, rewrite every H2 as a question that mirrors how someone would ask it in ChatGPT. Add a 40-60 word direct answer as the first paragraph under each H2. Apply the snippet test to every section. Then monitor citation changes across platforms over the next 30-60 days.
CompetLab's AI Visibility tracking monitors how ChatGPT, Claude, and Gemini mention your brand over time - so you can measure whether restructuring actually moves your citation rates. To set up measurement before you start restructuring, see How to Measure Your AI Visibility.
Frequently Asked Questions
Does content structure matter more than content quality for AI citations?
No. Content quality, authority, and relevance remain the foundation. Structure is a multiplier, not a replacement. The Princeton GEO experiments showed 30-40% visibility gains from structural changes alone, but those gains apply on top of existing content quality. Wikipedia gets cited heavily despite inconsistent structure because its authority is overwhelming. For most sites without Wikipedia-level authority, structure is where the marginal gains are largest.
How short should paragraphs be for AI extraction?
Target 100-300 words per extractable section, with the direct answer in the first 40-80 words. AI Overviews extract units that cluster around 134-167 words. Individual paragraphs within a section should be 2-4 sentences covering one idea. The goal isn't brevity for its own sake - it's semantic coherence. Each paragraph should be "about one thing" so the embedding captures complete meaning rather than averaging across multiple topics.
Do I need to restructure my entire site or just key pages?
Start with your top 10-20 pages by traffic or strategic value. Case studies show restructuring the highest-traffic content produces measurable citation changes within 60 days. Full-site restructuring isn't necessary upfront - identify which pages target queries that AI systems are answering, restructure those first, and measure the impact before scaling. The telehealth case study restructured 50 pages and saw 3x citation improvement.
Does this work equally for ChatGPT, Perplexity, and Google AI Overviews?
The core principles (question-format headings, answer-first sections, self-contained passages) work across all platforms, but emphasis differs. Google AI Overviews are most sensitive to heading hierarchy and passage structure. Perplexity weights freshness alongside structure and extracts shorter passages. ChatGPT responds more to content depth and data density than heading format specifically, but still shows strong first-third citation bias (44.2% from the top third).
How quickly do structural changes affect AI citation rates?
Faster than most SEO changes. The telehealth case study saw 3x citation increases within 60 days. TurboAudit's answer-first tests showed snippet capture tripling. For Perplexity specifically, changes can appear within days because it performs real-time web searches. Google AI Overviews typically reflect changes within 2-4 weeks as pages get recrawled and reindexed. The fastest path: restructure, reindex via Search Console, then test queries across platforms.
See your AI visibility
Find out how ChatGPT, Claude and Gemini answer when buyers look for tools like yours — where you show up, and against whom.
Share this article